AAAI Conference on Artificial Intelligence会议是人工智能领域重要的国际会议,是CCF A类推荐会议。AAAI 2026将于2026年1月20日-27日在新加坡举办。今年共有23680篇论文投稿,最终4167篇论文接收,录用率17.6%。厦门大学多媒体可信感知与高效计算教育部重点实验室共有38篇论文被录用,录用论文简要介绍如下(按第一作者姓氏笔画排序):
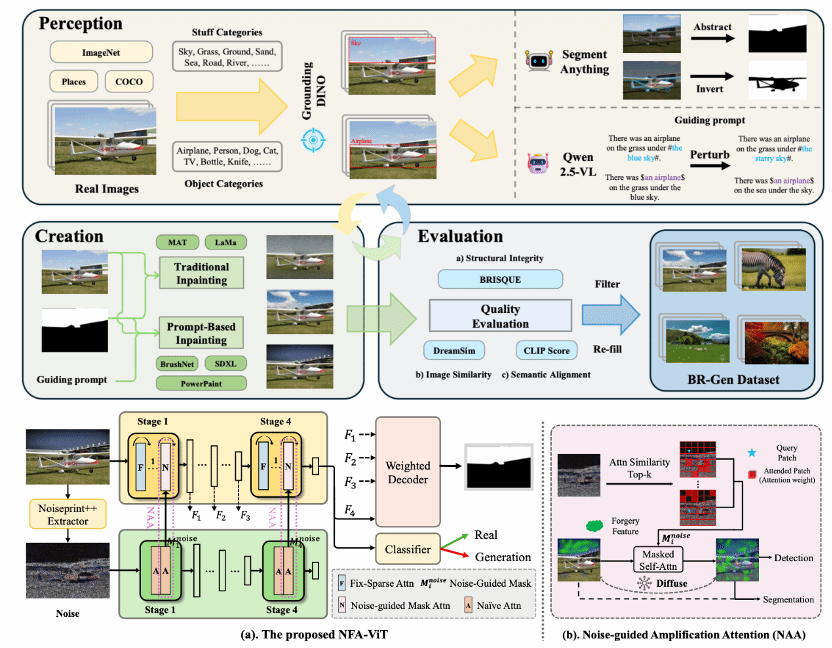
1. Zooming In on Fakes: A Novel Dataset for Localized AI-Generated Image Detection with Forgery Amplification Approach
随着生成式人工智能图像工具的迅速发展,基于AI的图像局部编辑日益逼真,给验证视觉内容完整性带来了新的挑战。目前检测数据集的局限在于过于关注物体(object-centric)伪造,而忽略了天空、地面等场景级元素(stuff and background),导致检测模型泛化能力不足。本文提出 BR-Gen——一个包含 150,000 张AI局部编辑图像的大规模数据集,具有多种场景感知标注。BR-Gen 通过全自动的“感知—生成—评估”流程构建,以确保语义一致性与视觉真实感。本文进一步提出 NFA-ViT——一种噪声引导的伪造增强方法,其能提升局部伪造检测能力。NFA-ViT 利用噪声指纹挖掘图像区域中的差异来源,并强制正常特征与异常特征交互,使伪造痕迹在整幅图像中传播,令细微伪造能够影响更广的上下文,从而提升模型检测的鲁棒性。大量实验表明,BR-Gen 构建了现有方法未覆盖的全新场景;NFA-ViT 在 BR-Gen 上超越现有方法,并在多个现有基准上表现出良好的泛化能力。项目代码可参见:https://github.com/clpbc/BR-Gen。
该论文的共同第一作者是厦门大学信息学院2024级硕士生蔡侣盼和腾讯优图王昊为,共同通讯作者是纪家沂博士后研究员和孙晓帅教授,由周门龑叔、陈燊(腾讯优图)、姚太平(腾讯优图)等共同合作完成。
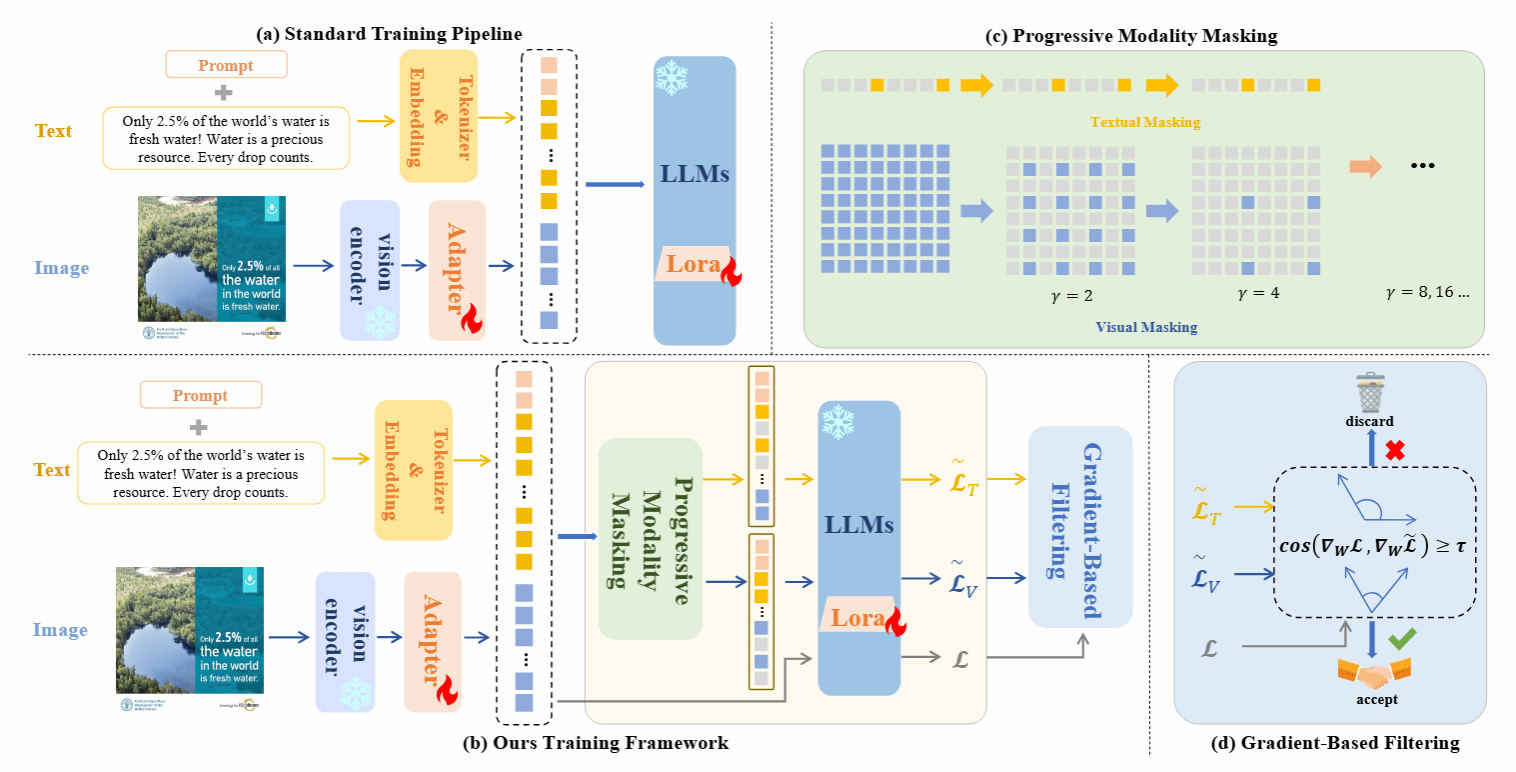
2. Augmenting Intra-Modal Understanding in MLLMs for Robust Multimodal Keyphrase Generation
尽管多模态大语言模型(MLLMs)在跨模态理解方面表现突出,但它们在处理噪声、缺失或模态错配的现实场景时表现出两类重要不足:一是弱化的单模态语义建模,即为追求跨模态关联而牺牲了对单一模态中细粒度线索的敏感度;二是模态偏置,某些MLLM倾向于过分依赖文本或视觉,从而忽视另一模态的关键信息。为此,本文提出了 AimKP 框架,以增强MLLM的单模态理解能力并保持跨模态对齐。AimKP包含两个核心部分:(1)渐进模态遮蔽,通过在训练过程中逐步遮蔽模态信息,迫使模型从被破坏的输入中提取细粒度特征;(2)基于梯度的筛选,通过梯度相似性动态剔除噪声样本,防止其影响核心跨模态学习。该方法首次系统性地将MLLM适配至MKP任务,实验结果也表明AimKP在多模态关键词生成任务中显著提升了模型的单模态理解能力和整体鲁棒性,取得了最新的最优性能。
该论文的第一作者是厦门大学数字媒体系2024级硕士研究生操佳俊,通讯作者是苏劲松教授和张庆刚博士(香港理工大学),由唐云波(厦门大学)、向志尚(厦门大学)和杨昶博士(香港理工大学)共同合作完成。
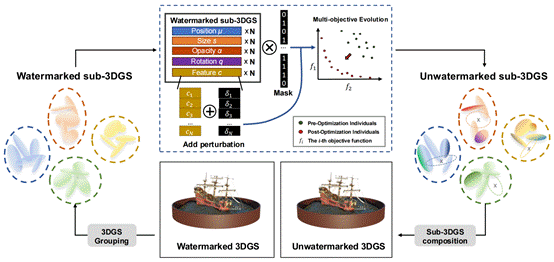
3. Fading the Digital Ink: A Universal Black-Box Attack Framework for 3DGS Watermarking Systems
3D高斯溅射作为一种新兴的3D场景表示和重建技术,凭借其高保真度和实时渲染能力,在电影、游戏、虚拟现实等领域展现了广阔的应用前景。随着3DGS模型的广泛应用,其版权保护问题日益凸显,多种数字水印技术被提出用于嵌入版权信息。然而,这些水印技术的鲁棒性(即抵抗潜在攻击的能力)尚未得到充分的研究。针对这一研究空白,该论文首次提出了一个通用的3DGS水印黑盒攻击框架GMEA(Group-based Multi-objective Evolutionary Attack)。该框架将攻击过程构建为一个大规模多目标优化问题,旨在同时实现两个相互冲突的目标:最大化水印去除效果与最小化视觉质量损失。在黑盒设置下(即攻击者对水印内容、嵌入和检测过程一无所知),GMEA创新性地设计了一个间接目标函数:通过最小化卷积网络提取特征的标准差,使特征图变得“平坦”且不具信息量,从而“致盲”下游的水印检测器。此外,为解决3DGS模型(通常包含数百万个高斯核)带来的巨大搜索空间,GMEA采用了一种基于分组的优化策略,利用聚类算法将模型划分为多个独立的子优化问题,显著提高了攻击效率。大量的实验结果表明,GMEA框架不仅能有效去除当前主流的一维和二维3DGS水印,同时能在攻击后保持极高的模型视觉保真度。该研究不仅揭示了现有3DGS版权保护方案中存在的关键漏洞,也为未来开发更安全、更鲁棒的水印系统提供了重要的基准和研究方向。
该论文第一作者是厦门大学信息学院2022级硕士研究生曾清源,通讯作者是江敏教授。并由蒋庶、林佳靖、王贞众助理教授、Kay Chen Tan教授(香港理工大学)共同完成。
4. 3D-DRES: Detailed 3D Referring Expression Segmentation
当前的三维视觉定位任务仅处理句子级别的检测或分割,这严重忽视了自然语言表达中丰富的组合性上下文推理。为解决这一挑战,本文提出“三维细节指向性分割”(3D-DRES)这一新任务,通过建立短语与三维实例的映射关系,提升精细的三维视觉语言理解能力。为支持3D-DRES,本文构建了包含54,432条文本、涵盖11,054个不同物体的DetailRefer数据集。与传统数据集不同,DetailRefer采用创新的短语-实例标注范式,每个指代名词短语都明确对应其三维元素。此外,本文还推出“DetailBase”架构——这种经过优化的基线模型在句子和短语层面均支持双模式分割。实验结果表明,基于DetailRefer训练的模型不仅在短语级分割中表现优异,更在传统三维指向性分割基准测试中取得显著突破。
该论文共同第一作者是厦门大学信息学院2023级硕士生陈琦和2024级博士生吴昌鲡,通讯作者为博士后研究员纪家沂,由2023级博士生马祎炜以及曹刘娟教授共同合作完成。
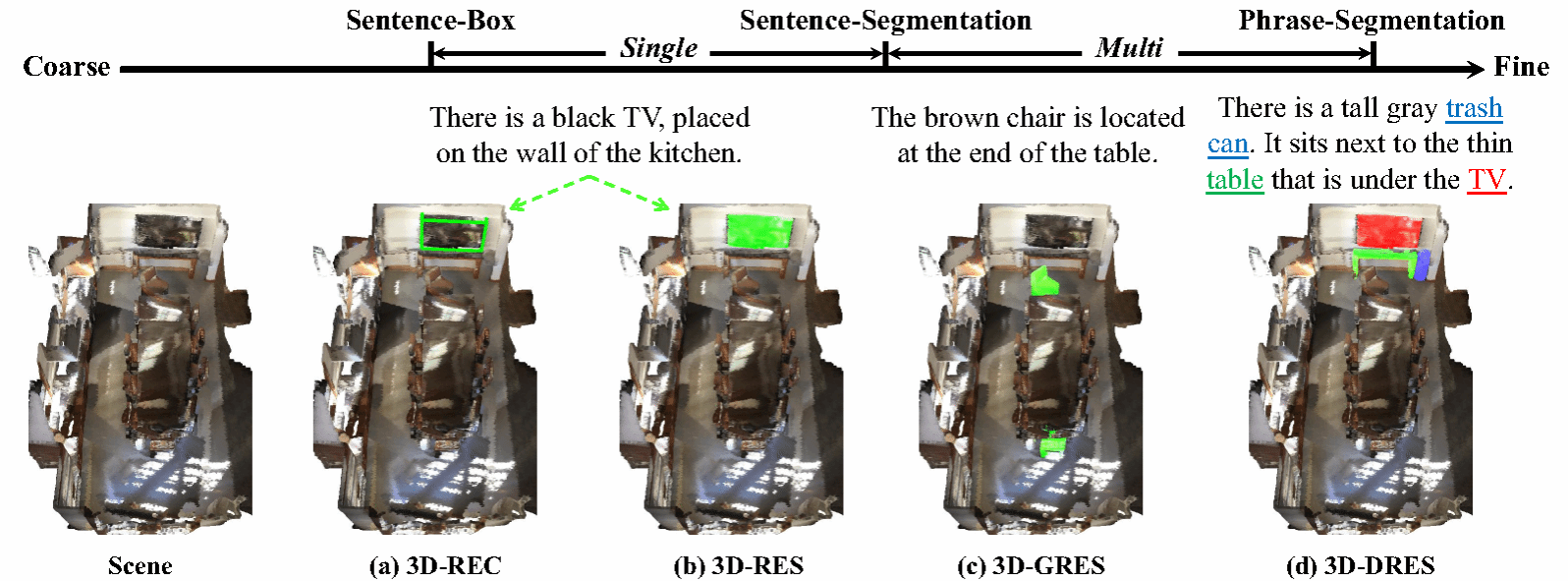
5. SAM2-OV: A Novel Detection-Only Tuning Paradigm for Open-Vocabulary Multi-Object Tracking
开放词汇多实例跟踪(OV-MOT)旨在同时处理已知与未知类别,但现有方法通常依赖从静态图像合成的伪序列数据,难以反映真实的运动模式,从而在跨帧关联上存在明显瓶颈。为解决这一问题,我们提出了一种仅基于检测调优范式的方法SAM2-OV,无需伪序列数据和时空信息的监督,显著减少可学习参数量。该方法的关键组件是统一检测模块(UDM),能够在关键帧上生成实例级提示,使SAM2能够适配开放词汇跟踪任务并发挥其零样本跨帧关联能力。同时为了提升在遮挡与急剧视角变换等极端场景下的关联质量,我们引入了运动先验辅助模块(MPAM),将运动信息引入SAM2掩码选择过程。同时,通过从CLIP蒸馏的语义增强适配器(SEA)提升模型语义表达能力,改善对其未见类别的分类泛化能力。而在推理过程中,我们通过引入稀疏提示的策略,仅在关键帧中执行检测,从而有效降低计算开销。由于只需在静态图像上调优检测模块,避免了对伪造序列数据的依赖,我们达到了简化OV-MOT方法训练过程的目的。在TAO数据集上的实验结果表明,SAM2-OV在TETA指标上具有明显的优势,特别是在新类别上的提升尤为显著,而KITTI数据集上的实验进一步证明了该方法在跨域场景下强大的零样本迁移能力。
该论文的第一作者是厦门大学信息学院2024级硕士研究生陈洋凯,通讯作者是王菡子教授。由吴强强(香港城市大学)、黎光耀、高俊龙助理教授以及牛广林助理教授(北京航空航天大学)共同合作完成。
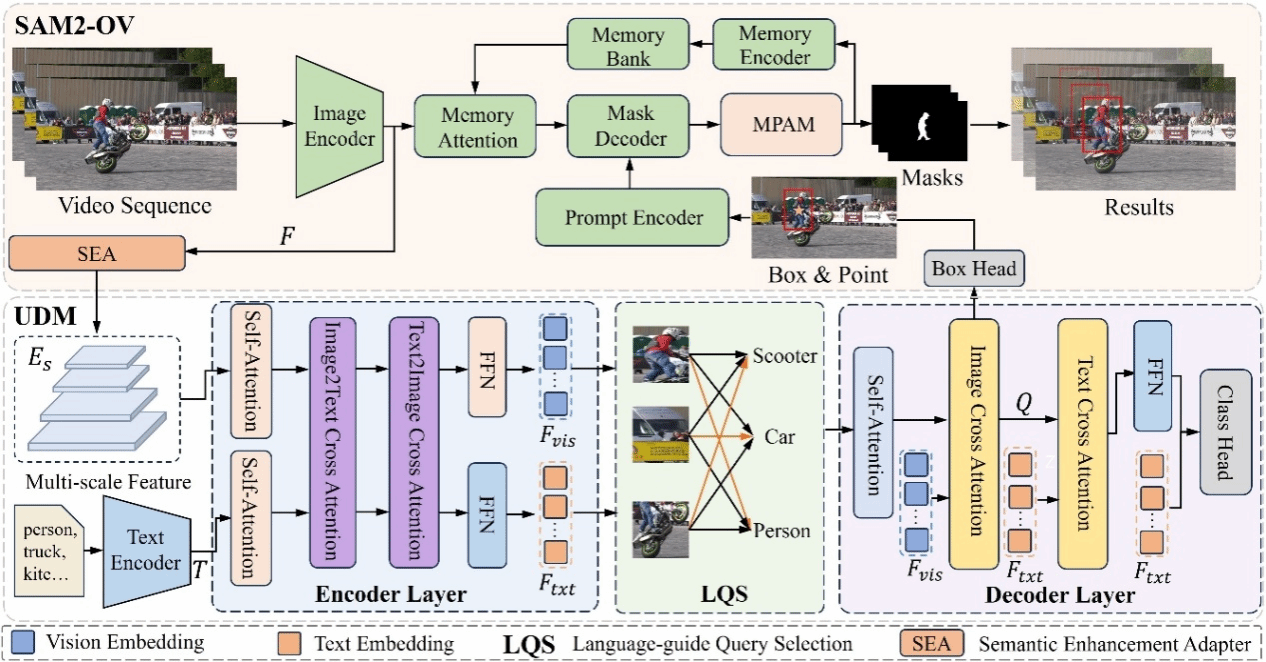
6. ARDiff: Anisotropic Residual Diffusion for Heterogeneous Graph Learning
异构图(Heterogeneous Graphs)在真实场景中广泛存在,但其多类型关系往往伴随噪声不均、语义跳变复杂等问题,导致现有方法难以准确捕获跨关系的语义演化。尤其在扩散框架下,传统各向同性高斯噪声无法反映异构图固有的结构方向性,易造成语义模糊与结构偏移。为此,我们提出ARDiff,一种结合语义残差建模与各向异性扩散的新型异构图学习框架。具体而言,ARDiff 包含两个核心设计:(i)语义残差扩散:基于从高噪声关系到低噪声关系的“语义链”,构建逐级残差去噪机制,以捕获关系间的细粒度语义差异;(ii)各向异性扩散策略:在前向扩散中引入结构与语义先验,生成方向性噪声;在反向扩散中结合随机游走位置编码,引导模型保持拓扑一致性。实验结果显示,ARDiff 在链接预测与节点分类任务上均显著超越现有方法,展现出更强的异构语义建模能力。
该论文的共同第一作者是厦门大学人工智能研究院2023级硕士生陈勇和李丽(深圳职业技术大学),通讯作者是苏松志副教授,由宗楠楠、刘志辉(真景科技)共同合作完成。
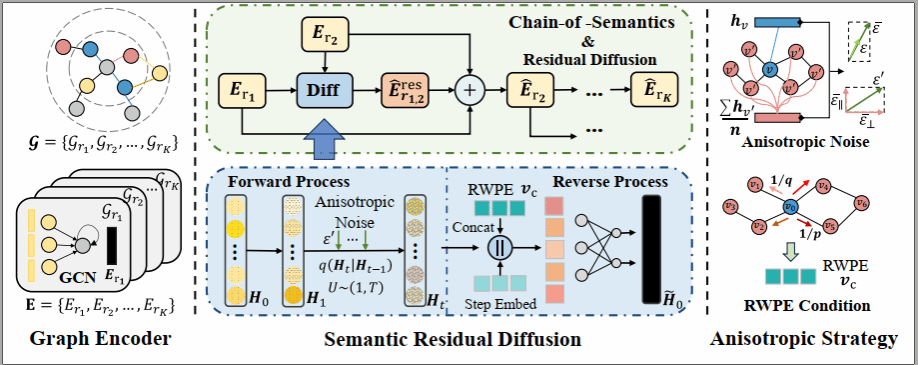
7. RFI: Rectified Flow Intervention for Mitigating Object Hallucination in Large Vision-Language Models(Oral)
大型视觉语言模型(Large Vision-Language Models, LVLMs)通过融合视觉与文本信息,在多模态理解与生成任务中展现出卓越的能力。然而,这类模型常常出现物体幻觉(object hallucination)问题,即生成的内容与输入图像不一致。现有缓解幻觉的方法主要存在两类局限:一方面,基于 logits 或注意力机制的动态方法容易过度抑制有价值的语言先验;另一方面,采用固定干预向量的静态方法缺乏对不同图像与问题的自适应能力。为了解决上述问题,我们提出了一种新方法——RFI(Rectified Flow Intervention)。RFI 利用校正流(rectified flow)的线性轨迹设计实现输入特定的自适应干预,并通过梯度校正(gradient correction)确保生成过程的一致性,从而有效结合了动态方法的自适应性与静态方法的稳定性。RFI 能够在仅需对每个问题进行一次前向传播的情况下,动态预测潜空间中的干预向量,从而兼顾计算效率(生成100个新 token 的延迟开销仅为1.09倍)。大量实验结果表明,RFI 在显著降低幻觉现象的同时,较现有先进方法取得更优性能,充分展示了其作为一种轻量级、即插即用的 LVLM 幻觉抑制方案在实际应用中的有效性。
该论文第一作者是厦门大学信息学院2025级硕士生程俊羽,共同通讯作者是陈毅东副教授和华南师范大学李双印副教授,由梁志标(华南师范大学)等共同合作完成。
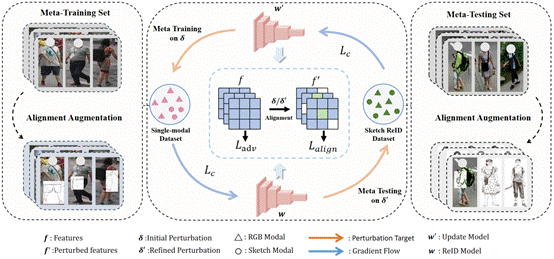
8. A Theory-Inspired Framework for Few-Shot Cross-Modal Sketch Person Re-Identification(Oral)
素描行人重识别旨在将手绘草图与 RGB 图像进行匹配,但由于模态差异显著且标注数据稀缺,该任务仍面临巨大挑战。为此,本文提出KTCAA,一个理论启发的、适用于小样本跨模态迁移学习的框架。从泛化误差上界的角度出发,识别出影响目标域误差的两个关键可控因素:(1)域差异性,即源域与目标域在特征空间中的分布对齐难度;(2)扰动不变性,即模型对跨模态变化的鲁棒性。针对上述挑战,本文设计了两个相应的模块:(1)对齐增强模块,通过对 RGB 图像进行局部草图风格变换,引入细微但有意义的特征扰动,从而引导模型逐步对齐不同模态的分布;(2)知识迁移催化器,通过生成最坏情况下的模态扰动,并强制保持特征输出一致性,以提升模型的扰动鲁棒性。上述两个模块在元学习框架下联合优化,使得模型能够有效地将RGB数据集中丰富的知识迁移到素描场景。多项基准测试结果表明,KTCAA 在数据有限和跨模态迁移条件下均实现了领先的识别性能和出色的泛化能力。
该论文第一作者是厦门大学信息学院2023级博士研究生龚云鹏,通讯作者是江敏教授。并由侯永杰(电子科学与技术学院)、施江鸣(人工智能研究院)、叶金龙共同完成。
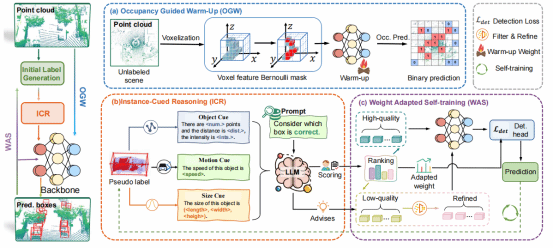
9. OWL: Unsupervised 3D Object Detection by Occupancy Guided Warm-up and Large Model Priors Reasoning
无监督三维目标检测通过启发式算法发现潜在目标,为自动驾驶降低标注成本提供了有效途径。现有方法主要通过生成伪标签并进行自训练迭代来优化模型,但这些伪标签在训练初期往往存在错误。为此,本文提出基于占用引导预热和大模型先验推理的无监督目标检测方法OWL。首先采用占用引导的自监督预热策略学习场景特征,有效缓解错误伪标签对网络收敛的干扰;其次引入实例线索推理模块,利用大模型先验知识评估与优化伪标签质量;最后设计自适应权重自训练策略提升模型性能。在Waymo和 KITTI 数据集上的实验表明OWL显著优于SOTA无监督方法。
该论文第一作者是硕士生郭徐晟,通讯作者是温程璐教授、博士毕业生吴海助理研究员(鹏城实验室)。并由张万发、赵世佳、夏启明、王明明(GAC R&D Center)共同合作完成。
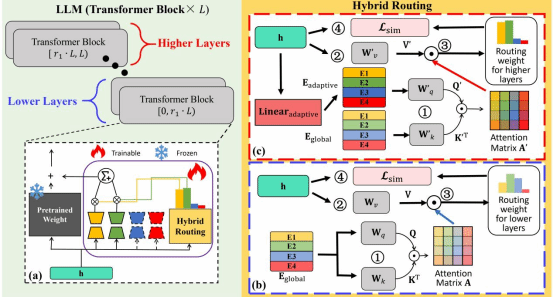
10. Hybrid Routing for a Mixture of LoRA Experts
本文提出了一种名为HotMoE 的异构路由混合LoRA专家模型框架,旨在解决多任务指令微调中专家利用效率低和专家与任务适配不足的问题。HotMoE 引入分层混合路由机制,在浅层促进跨任务协作与泛化,在深层实现任务语义与专家能力的精确对齐。此外,提出相似度引导的辅助损失,增强专家专化性与路由确定性。实验结果表明,HotMoE 在多个自然语言理解与大模型生成任务上显著优于现有多任务微调方法,有效缓解了多任务学习中的“跷跷板效应”。
该论文第一作者是硕士生黄逸桐,通讯作者是范晓亮高级工程师。并由杨子棋、王子徽(鹏城实验室)、Jianzhong Qi (墨尔本大学)、俞容山教授、王程教授共同合作完成。
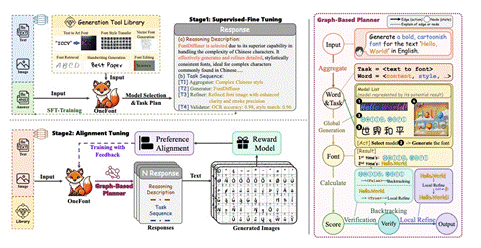
11. OneFont: A Unified Agent for End-to-End Font Creation
尽管最近在字体生成方面取得了进步,但从业者仍然在艰难的试错工作流程中挣扎。为了简化这一点,我们提出了OneFont,这是一个端到端的框架,通过自由形式的对话来解释用户的意图,无缝地集成了字形合成和细化模块。我们介绍了带有思想的字体(FwT)范式重构字体设计作为推理任务其中的模型 计划行动并阐明设计原理。OneFont通过两个阶段的训练来掌握 这个范例。首先,我们通过监督微调(SFT)在我们建立的1500个字体家族的新的综合基准上灌输推理能力。第二,我们提炼采用一种新的强化学习算法GRPO来指导模型的策略 通过评估视觉保真度、基本原理一致性和转换正确性的混合奖励。大量的实验表明,OneFont明显优于现有的方法。
该论文第一作者是厦门大学信息学院2022级博士研究生赖映鑫,通讯作者是罗志明副教授。并由刘宇菲、杨国庆、柴家星、李绍滋教授共同完成。
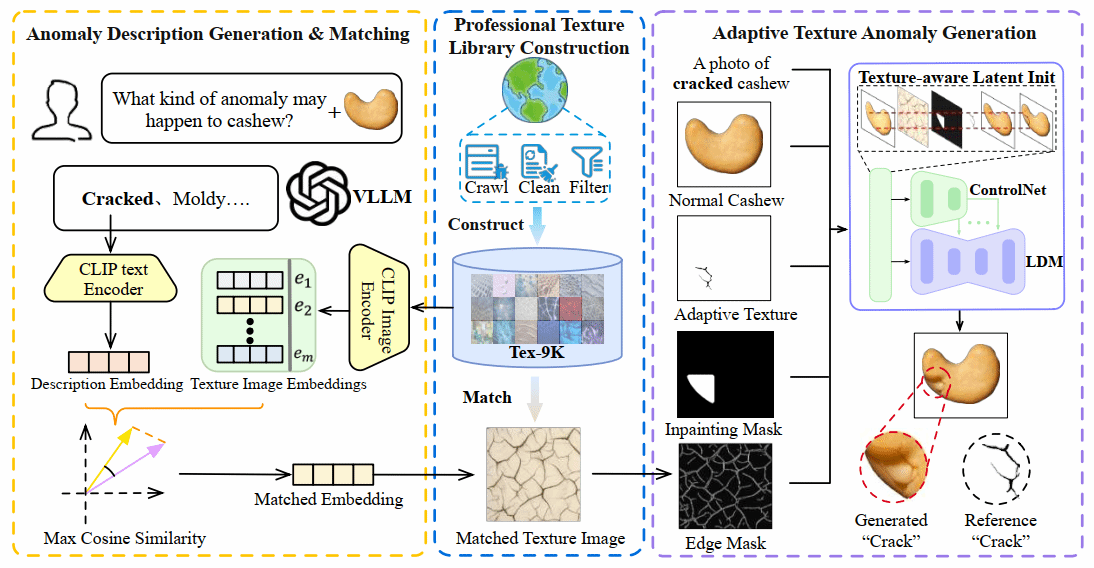
12. AnomalyPainter: Vision-Language-Diffusion Synergy for Realistic and Diverse Unseen Industrial Anomaly Synthesis
视觉异常检测由于缺乏足够的异常数据而受到限制。尽管现有的异常合成方法已经取得了显著进展,但在同时兼顾合成结果的真实感和多样性方面仍面临巨大挑战。为了解决这一问题,本文提出了 AnomalyPainter框架,这一新框架通过协同利用视觉语言大模型、潜在扩散模型以及本文新构建的纹理库 Tex-9K,打破“多样性–真实感”的权衡困境。Tex-9K 是一个专业纹理库,包含 75 个类别、共 8792 个纹理素材,专门为多样化异常合成而设计。借助 VLLM 的通用知识,本文为每一种工业目标自动生成合理的异常文本描述,并与 Tex-9K 中相关且多样的纹理进行匹配;这些纹理随后通过 ControlNet 引导 LDM 在正常图像上进行“绘制”。大量实验表明,AnomalyPainter 在真实感、多样性和泛化能力方面均优于现有方法,并在下游任务中取得了更好的性能。
该论文共同第一作者是厦门大学信息学院2023级硕士生赖章宇和卢轶霖,通讯作者为曹刘娟教授,由2023级博士生李新阳、林将航、曲延松,李明(浪潮)共同合作完成。
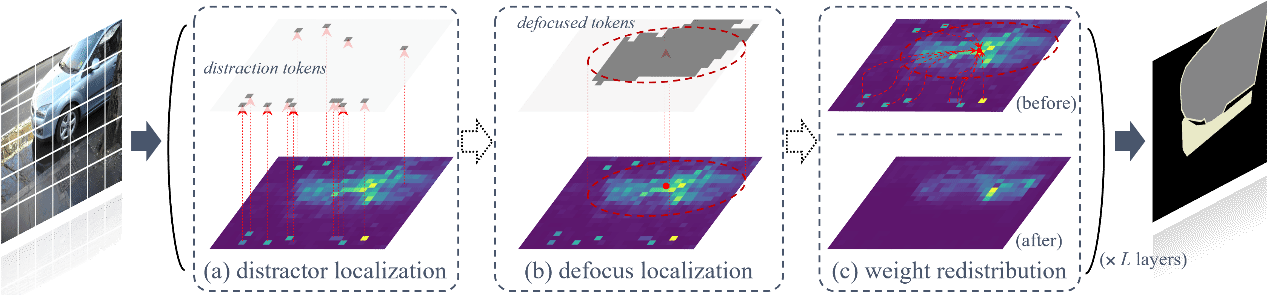
13. Target Refocusing via Attention Redistribution for Open-Vocabulary Semantic Segmentation: An Explainability Perspective
开放词汇语义分割通过像素级的视觉-语言对齐技术,将类别相关提示与对应像素建立关联。其核心挑战在于提升多模态密集预测能力——尤其是像素级的多模态对齐性能。现有方法虽借助CLIP的视觉-语言对齐能力取得显著成果,却鲜少从解释性机制视角探究CLIP在密集预测任务中的性能边界。本研究系统揭示了CLIP的内部机制,发现关键现象:类比人类分心行为,CLIP会将大量注意力资源从目标区域转移至无关token。分析表明,这些干扰token源于维度特异性过激活现象,过滤此类token可显著增强CLIP的密集预测性能。据此,本文提出ReFocusing CLIP方法(简称RF-CLIP),这种无需训练方案通过模拟人类"分心-再聚焦"行为,将注意力从干扰token重定向至目标区域,从而提升CLIP多模态对齐的精细度。本方法在八大基准测试中刷新最先进性能,同时保持高效推理效率。
该论文第一作者是厦门大学信息学院2023级博士生李佳豪,通讯作者是其导师曲延云教授和谢勇教授(南京邮电大学),目前主要研究方向为多模态感知的复杂开放场景理解。
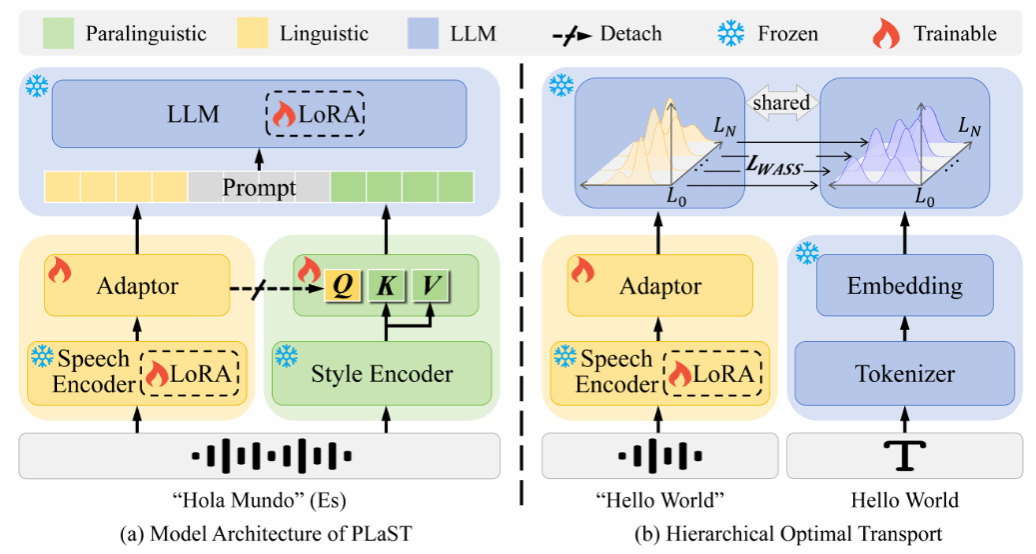
14. PLaST: Towards Paralinguistic-aware Speech Translation (Oral)
语音翻译(Speech Translation, ST)旨在将源语言语音直接翻译为目标语言文本。然而,语音信号中除语言内容外,还包含语气、情感、强调等副语言线索(paralinguistic cues),这些信息可能显著影响甚至改变语义解读,从而导致不同的翻译结果。现有ST模型普遍缺乏对副语言信息的直接且充分建模,难以全面感知语音中的语用细微差别,限制了翻译性能的进一步提升。为此,本文提出了一种副语言感知的语音翻译框架(ParaLinguistic-aware Speech Translation, PLaST),通过双分支结构显式分离并融合语言与副语言信息。具体而言,PLaST利用语音编码器与风格提取器分别生成语言表征和副语言表征;为进一步获得与文本对齐的纯净语言表征,引入分层最优传输(Hierarchical Optimal Transport)机制对大语言模型解码器的层间输出进行约束;随后,设计基于注意力的检索模块(Attention-based Retrieval, AR),以语言表征为查询,动态检索并精炼副语言信息,实现语义理解与翻译生成的联合引导。在副语言敏感基准ContraProST上的实验表明,PLaST显著优于现有强基线方法;同时在标准语音翻译数据集CoVoST-2上也展现出良好的泛化能力,验证了该方法的有效性与实用性。
该论文的共同第一作者是厦门大学信息学院2024级硕士生李一和2025级博士生赵瑞,通讯作者是陈毅东副教授,由张睿诠、苏劲松教授、魏代猛(华为研究院)、张敏(华为研究院)等共同合作完成。
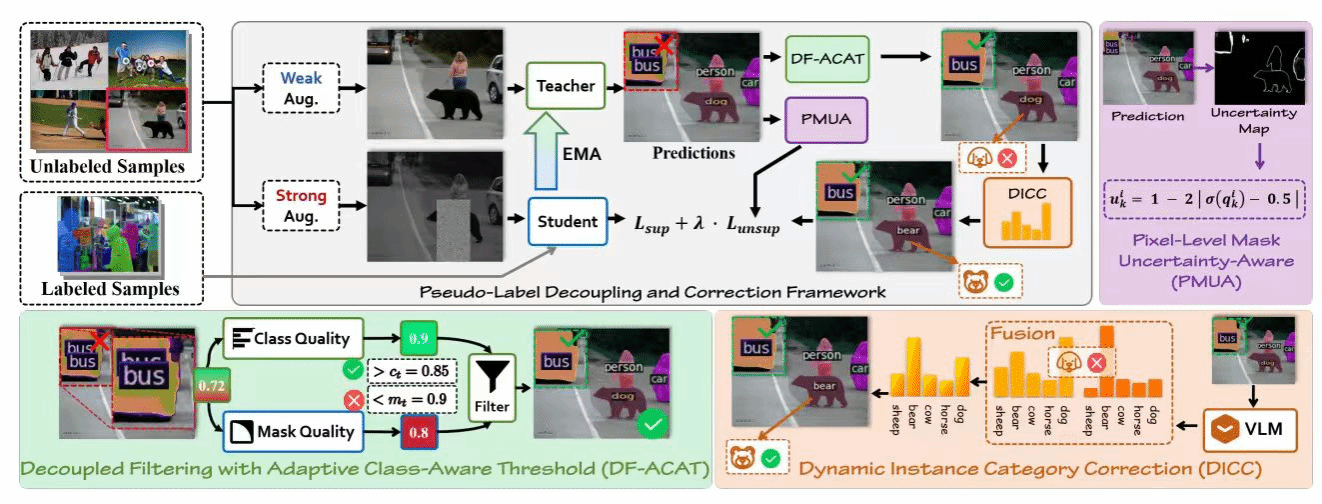
15. Robust Pseudo-Labeling via Decoupled Class-Aware Filtering and Dynamic Category Correction(Oral)
半监督实例分割(SSIS)旨在利用有限的标注数据与大规模未标注数据实现实例级预测,但其性能高度依赖伪标签质量。现有方法通常将类别置信度与掩码质量耦合为单一分数进行过滤,容易造成语义准确性与空间精度之间的冲突,从而引入噪声伪标签并限制模型上限。
为此,本文提出 PL-DC(Pseudo-Label Decoupling and Correction) 框架,从实例、类别与像素三个层面全面提升伪标签的可靠性。首先,设计解耦过滤与自适应类别感知阈值机制,分别评估类别与掩码质量,并通过指数移动平均动态更新类别特定阈值,实现更细粒度的伪标签筛选。其次,提出动态实例类别校正模块,利用语义原型与一致性对齐策略纠正类别模糊的伪标签。最后,引入像素级掩码不确定性感知机制,抑制低置信像素的干扰,提高掩码监督的精确性和鲁棒性。在 COCO 与 Cityscapes 基准上的大规模实验表明,PL-DC 在极低标注比例下依然带来显著提升,在COCO 1% 标注数据上提高 +11.7 mAP,在 Cityscapes 5% 标注下提升 +16.4 mAP,并取得新的 SOTA 结果,充分展示了其在弱标注场景中的强大优势。
该论文第一作者是厦门大学信息学院2023级博士生林将航,通讯作者是张声传教授,由2023级硕士生卢轶霖、2025级博士生朱朝阳、腾讯优图沈云航、曹刘娟教授等共同合作完成。
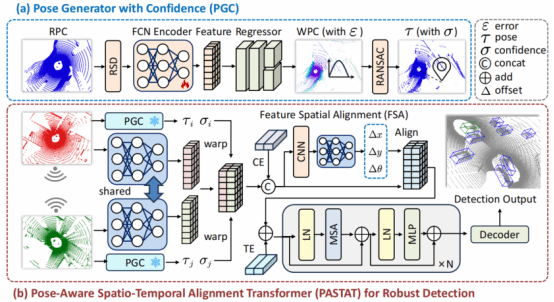
16. V2VLoc: Robust GNSS-Free Collaborative Perception via LiDAR Localization
多智能体依赖于精确的姿态信息共享和对齐观测数据,以实现对环境的协同感知。然而,现有定位方法在GNSS信号受限环境下容易失效,导致难以实现一致的感知特征对齐。为此,本文提出一种基于激光雷达定位的无GNSS协同目标感知框架。首先提出了轻量级的置信度姿态生成器估计紧凑的姿态和置信度表示,其次设计了姿态感知时空对齐变换器,在捕获关键时间上下文的同时,执行置信度感知的空间对齐。此外,提出一个新的仿真数据集V2VLoc,用于验证定位和协同检测任务。在 V2VLoc和V2V4Real 数据集上的实验验证了本方法的有效性和泛化能力。
该论文第一作者是硕士生林文铠,通讯作者是温程璐教授。并由夏启明、李文、黄勋共同合作完成。
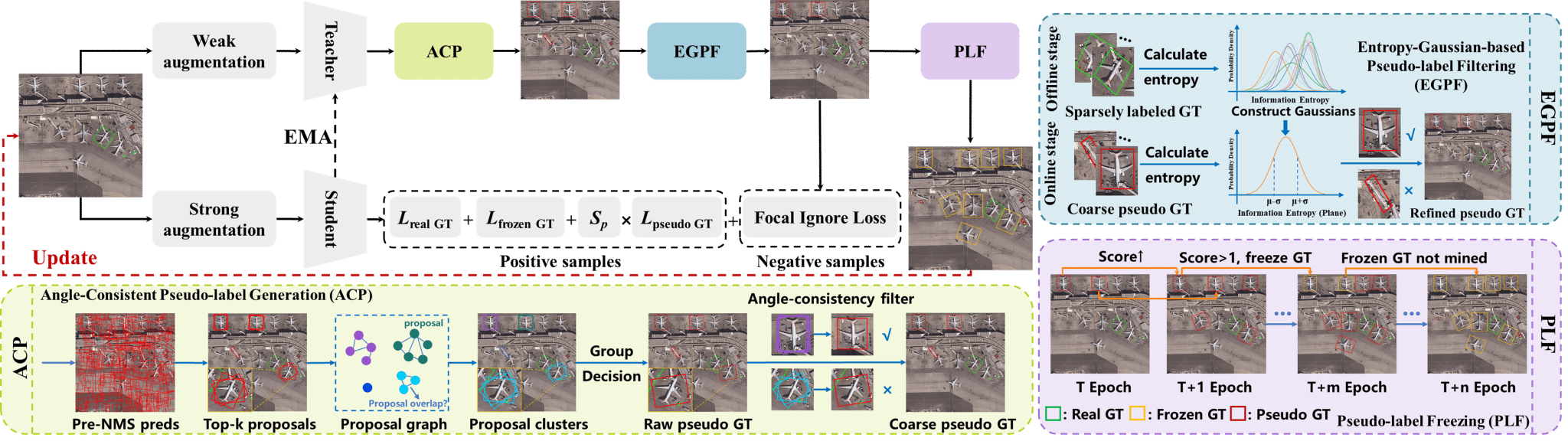
17. S2Teacher: Step-by-step Teacher for Sparsely Annotated Oriented Object Detection(Oral)
虽然全监督的旋转目标检测在遥感图像理解方面取得了显著进展,但其代价是高强度的人工标注。近年来的研究尝试通过弱监督与半监督学习来缓解这一负担但这些方法忽略了复杂遥感场景中密集标注所带来的困难。本文提出了一种新的任务设定——稀疏标注旋转目标检测(SAOOD),其中每幅图像仅标注部分实例,并进一步提出了解决该设定挑战的方法。具体而言,本文关注该设定中的两个关键问题:(1) 稀疏标注导致模型在有限的前景表征上发生过拟合;(2) 未标注目标(即假负例)会干扰特征学习,提出了S2Teacher,这是一种新的角度一致性引导方法,可由易到难逐步挖掘未标注目标的伪标签,从而增强前景表征;同时,它会对未标注目标的损失进行重加权,以减轻其在训练过程中的影响。大量实验表明,S2Teacher在不同稀疏标注比例下均能显著提升检测器性能,并且在仅使用10%标注实例的情况下,在DOTA数据集上取得接近全监督的性能,有效平衡了精度与标注成本。
该论文第一作者为厦门大学2024级博士生林煜,通讯作者为曹刘娟教授,由林将航博士、张声传副教授等共同合作完成。
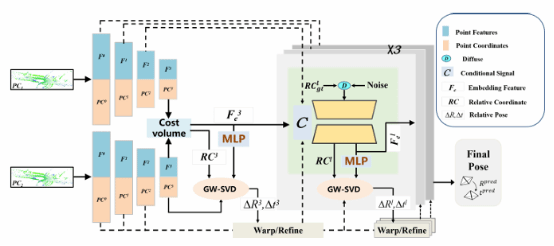
18. RCP-LO: A Relative Coordinate Prediction Framework for Generalizable Deep LiDAR Odometry
基于学习的激光雷达里程计方法通过端到端回归相对位姿展现了优越性能,然而当迁移到新场景时性能显著降低。为此,本文提出一种简洁而高效的激光雷达里程计框架RCP-LO。首先,创新性地将相对位姿表示为相对坐标并基于几何验证进行求解,避免了过度简化的位姿表示。其次,为捕捉动态环境中遮挡点云相对位姿估计固有的不确定性,引入去噪扩散模型进行相对坐标采样,在增强鲁棒性的同时生成合理位姿假设。还设计了可微分加权奇异值分解模块,通过单次前向传播即可实现高效位姿估计。实验表明,仅在KITTI数据集上进行训练,在KITTI-360、Ford和Oxford数据集上均达到与当前最优学习方法相当的精度。
该论文第一作者是硕士生刘晨、博士毕业生李文,通讯作者是王程教授。并由黄泳树、朱明航、杨煜阳、刘敦强及敖晟助理教授共同完成。
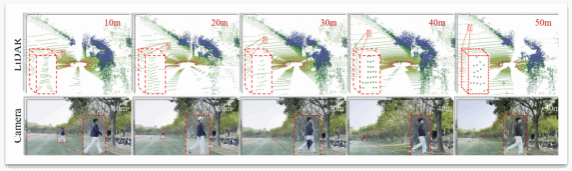
19.Walking Further: Semantic-aware Multimodal Gait Recognition under Long-Range Conditions
步态识别能通过人的行走方式实现非接触、难伪造的身份识别。然而,现有的方法仍局限于近距离、单模态场景,在复杂的真实环境中难以适应远距离或跨距离识别需求。为解决这一问题,本文提出首个面向远距离、室外多场景的LiDAR-相机多模态步态识别基准数据集LRGait。此外,本文设计一个全新的端到端框架EMGaitNet,专为远距离多模态步态识别而优化,通过语义引导的多模态融合策略,有效弥合了RGB图像与点云数据之间的模态差距。
该论文第一作者是博士生陆志阳,通讯作者是程明教授。并由江文、吴天任、王志超、沈思淇长聘副教授、张长旺高级研究员(OPPO研究院)共同合作完成。
20. QuoTA: Query-oriented Token Assignment via CoT Query Decouple for Long Video Comprehension
QuoTA是一种面向长视频理解任务设计的查询驱动免训练插件,通过“思维链”提示先对大模型进行问题拆解,把复杂指令转化为包含具体实体或事件的关键词列表,再调用轻量级LVLM并行评估每一帧与查询的相关度,生成帧级重要性得分;随后在不改变总视觉token预算的前提下,利用双线性插值、自适应池化或动态token融合三种策略对得分高的帧多分配token、得分低的帧少分配甚至舍弃,并配合依视频长度自适应增加的采样帧数,实现细粒度且高效的视觉冗余压缩。实验表明,将QuoTA直接插入LLaVA-Video-7B或LLaVA-OneVision-7B后,在Video-MME、MLVU、LongVideoBench、VNBench、MVBench与NeXT-QA六项涵盖分钟级到小时级视频的基准上平均性能提升3.2%,其中最长30–60分钟段落的Video-MME提升达4–5个百分点,VNBench“大海捞针”式检索任务提升更高达10.3%,验证了查询感知token分配在缓解信息冗余、增强关键帧表达及提升长视频推理能力方面的显著优势。
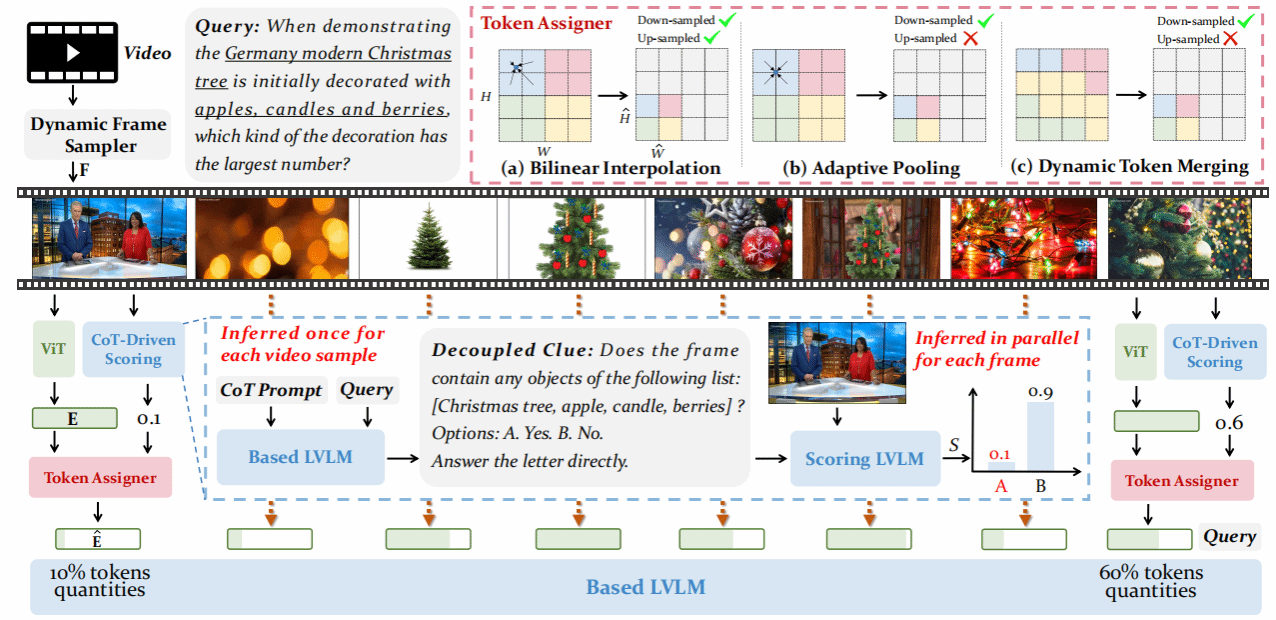
该论文共同第一作者为厦门大学信息学院2023级硕士生罗咏东和2024级硕士生陈旺,通讯作者是郑侠武副教授,由纪家沂博士后研究员、黄锦发(罗切斯特大学)等共同合作完成。
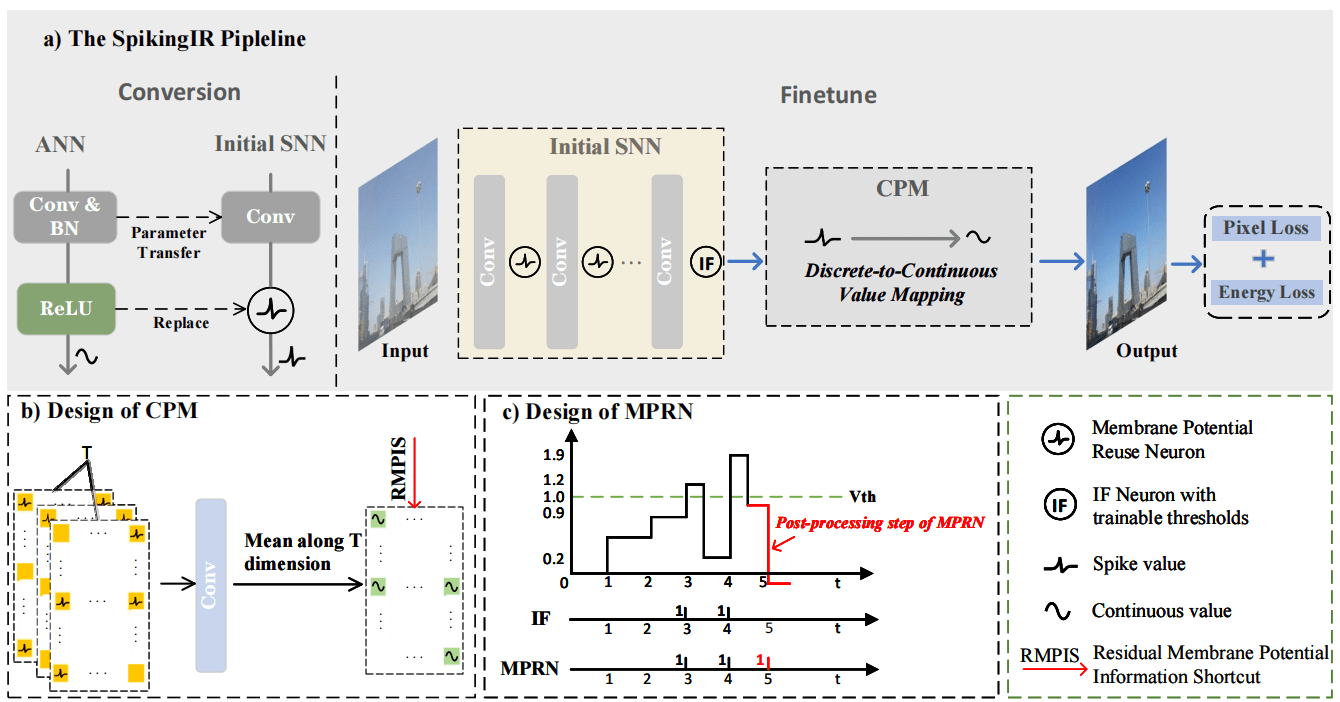
21. SpikingIR: A Novel Converted Spiking Neural Network for Efficient Image Restoration
脉冲神经网络(SNN)因其事件驱动机制和低能耗特性,被视为替代传统人工神经网络(ANN)的理想方案,但在图像恢复等对输出精度高度敏感的低层视觉任务中,其离散脉冲表示易引入量化误差与信息损失,严重制约了性能表现。针对这一问题,本文提出了一种面向图像恢复任务的ANN-to-SNN转换框架 SpikingIR。该框架围绕输出层与中间层的量化误差与信息损失问题,分别引入卷积像素映射模块(CPM)和膜电位复用神经元(MPRN):CPM通过卷积操作将离散脉冲输出映射至连续空间,并结合残余膜电位信息增强像素级表示能力;MPRN则通过额外的后处理步骤充分释放神经元残余膜电位,减少信息丢失,从而提升整体表达精度。在此基础上,结合能耗约束的微调策略,SpikingIR 在去雾、去噪和超分辨率任务中实现了在极少时间步下接近ANN模型的性能,同时显著降低能耗,展现出良好的效率优势与实际应用潜力。
该论文的第一作者是厦门大学信息学院2024级硕士生欧阳洋,通讯作者是曲延云教授,信息学院2024级硕士生程梓涵、罗小同(香港理工大学)、李国齐研究员(中国科学院自动化研究所)共同合作完成。
22. DeOcc-1-to-3: 3D De-Occlusion from a Single Image via Self-Supervised Multi-View Diffusion
本文提出DeOcc-1-to-3,首个支持从遮挡图像直接进行3D补全与重建的端到端方法。该框架基于预训练多视角扩散模型,通过结构保持的自蒸馏训练策略,联合学习图像补全与多视角合成,无需修改原始架构即可获得高质量、结构一致的新视图,显著提升遮挡场景下的3D重建效果。此外,本文还构建了首个系统性遮挡三维重建评测基准Occ-LVIS,涵盖多类别与多等级遮挡,支持细粒度评估。实验证明,DeOcc-1-to-3在重建完整性与视觉质量方面均优于两阶段方法,同时具备良好的推理效率与泛化能力。
该论文第一作者为厦门大学信息学院2023级博士生曲延松,通讯作者是张声传副教授,由2024级硕士生代绍辉、2023级博士生李新阳、王宇泽(北京航空航天大学)、2024级博士生沈优、曹刘娟教授等共同合作完成。

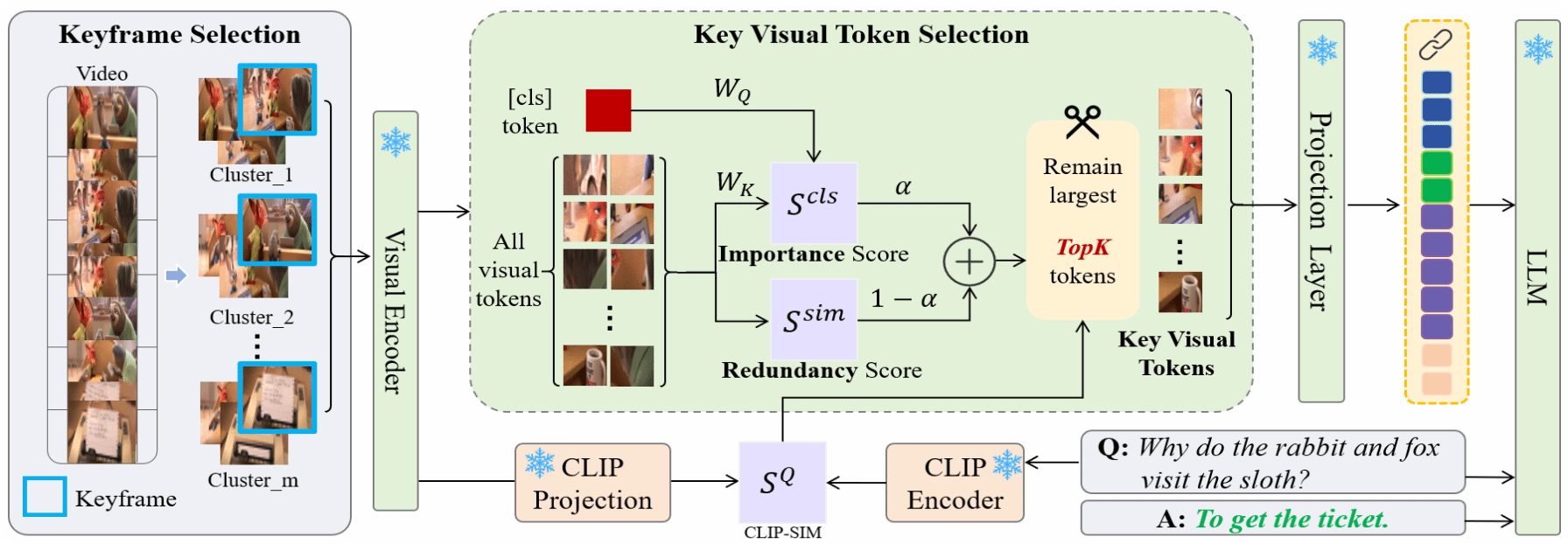
23. KTV: Keyframes and Key Tokens Selection for Efficient Training-Free Video LLMs
本文提出了一个名为 KTV的免训练的视频理解框架,通过“两级筛选”让通用图像-文本大模型更高效地看视频:第一步,它不用问题信息,而是用 DINOv2 提取所有帧的特征并做 K-means 聚类,从中选出能代表整段视频、且内容多样的问题无关关键帧以避免落入“语义陷阱”,从而减少时间上的冗余;第二步,在每个关键帧内,再根据与[CLS] token的重要性得分和与其他视觉token的冗余度共同计算评分,只保留最有信息量、又不过于重复的关键视觉 token,并结合CLIP评估与问题的相关性,为更相关的帧分配更多token,最终将这些精简后的视觉token与文本一起输入LLaVA等VLM进行推理。实验表明,在多项多选视频问答基准上,KTV在仅用极少视觉token(例如60分钟、10800帧的视频只用 504 个视觉 token)的情况下,仍优于现有免训练的视频理解方法,部分设置甚至超过一些需要专门训练的视频大模型,显著降低了推理时长和算力需求。
该论文的共同第一作者是厦门大学信息学院2025级硕士生宋柏杨和鹏城实验室博士后研究员彭军,共同通讯作者是博士后研究员彭军(鹏城实验室)和郭健元助理教授(香港城市大学)。由2022级博士生张玉鑫、陈光耀(北京大学)、杨飞雕(鹏城实验室)共同完成。
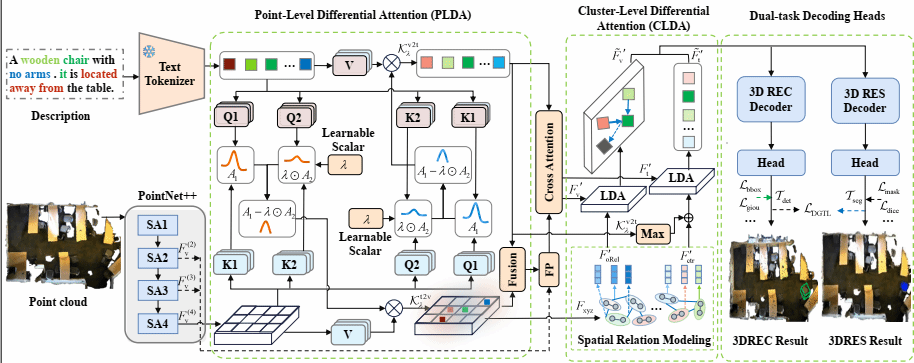
24. PC-CrossDiff: Point-Cluster Dual-Level Cross-Modal Differential Attention for Unified 3D Referring and Segmentation
针对当前3D视觉定位(3DVG)方法在多目标复杂场景下面临的两大关键瓶颈——隐式定位线索解析能力不足与空间匹配关系干扰抑制缺失,本文提出一种基于点-簇协同优化的跨模态差分学习网络(PC-CrossDiff)。该方法通过点层级跨模态差分注意力,自适应提取文本描述中的隐式定位线索,有效缓解文本潜在语义丢失问题,显著增强模型在多目标场景下的定位判别能力;同时,引入簇级差分注意力,通过差异化建模空间匹配关系并动态抑制无关干扰,解决定位关联关系的选择性提取难题。通过点级局部语义感知与簇级全局关系筛选的协同建模机制,PC-CrossDiff统一建模3D指代表达式理解(3DREC)与3D指代表达式分割(3DRES)任务。该方法无需复杂的投影流程,在保持高推理速度的同时,显著提升了多目标复杂场景下的定位精度与鲁棒性,为3D视觉定位提供了一种新的双任务学习范式。
该论文第一作者是厦门大学信息学院2024级博士生谭文斌,共同通讯作者为张亚超助理教授和谢勇教授(南京邮电大学),由2024级硕士生林嘉文、谢源教授(华东师范大学)和曲延云教授等共同完成。
25. Diffusion Once and Done: Degradation-Aware LoRA for Efficient All-in-One Image Restoration
扩散模型在一体化图像恢复(AiOIR)中展现出强大的潜力,尤其擅长生成丰富的纹理细节。现有的 AiOIR 方法通常需要重新训练扩散模型,或者在预训练扩散模型的基础上加入额外的条件引导进行微调。然而,这些方法往往面临推理成本高、对多样化退化类型适应性有限的问题。本文提出了一种高效的 AiOIR 方法——Diffusion Once and Done(DOD),旨在仅通过 Stable Diffusion(SD)模型的一步采样就实现优异的恢复性能。具体而言,首先引入了多退化特征调制机制,通过预训练的扩散模型来捕获不同的退化提示;随后,参数高效的低秩条件适配方法将这些提示进行融合,从而使 SD 模型能够通过微调适应多种退化类型。此外,本文在 SD 的解码器中集成了高保真细节增强模块,以提升结构与纹理细节。实验结果表明,本文方法在视觉质量与推理效率方面均优于现有基于扩散模型的图像恢复方法。
该论文共同第一作者为厦门大学信息学院2024级博士生唐妮和香港理工大学罗小同,通讯作者为曲延云教授,由程梓涵、周亮太、张东晓(集美大学)共同合作完成。
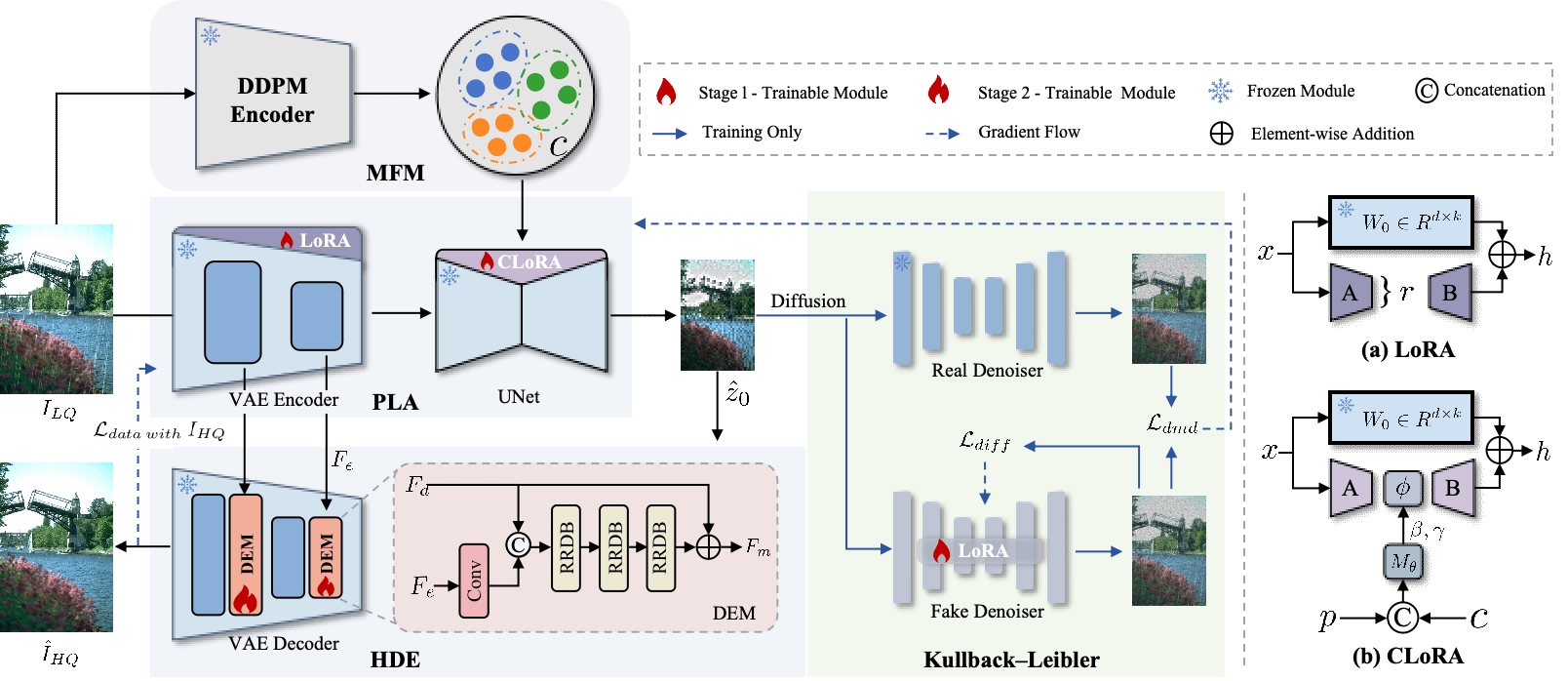
26. Beyond Passive Critical Thinking: Fostering Proactive Questioning to Enhance Human-AI Collaboration
简介:近年来,基于大模型的智能体技术取得了显著突破,已在多项任务中达到专家水平。然而,现有智能体大多仍被动接收人类指令,缺乏主动与人协作完成任务的能力,这限制了其在现实复杂场景中的应用。具体而言,当用户提供的任务指令存在瑕疵时,传统方法往往执行错误推理或直接拒绝回答,而无法主动向用户提问以澄清问题,从而影响了任务完成效率。为探究这一问题,本文通过构建带有缺失条件的数学问题,设计了一个依赖人机协作的任务场景,并在此框架下评估了现有模型在主动协作能力方面的表现。此外,本文进一步证明,采用强化学习技术能够有效引导智能体通过思维链推理,逐步学会提出更准确的问题,从而实现更高效的人机协作。
该论文共同第一作者是厦门大学信息学院2022级博士王安特、2023级硕士林渝杰和2025级硕士刘靖瑶,通讯作者是苏劲松教授,由2023级硕士吴苏航、刘昊(百度)、肖欣延(百度)共同合作完成。

27. Self-supervised Multiplex Consensus Mamba for General Image Fusion (Oral)
图像融合通过整合不同模态的互补信息,生成高质量的融合图像,从而提升目标检测、语义分割等下游任务的表现。不同于面向单一任务的专用融合方法,通用图像融合旨在不增加复杂度的前提下,实现更广的任务范围并提升性能。为此,本文提出一种用于通用图像融合的自监督多路共识 SMC-Mamba框架。首先,该框架创新性地设计了模态无关特征增强(MAFE)模块,通过自适应门控保留局部精细细节,并以空间通道与频率旋转扫描强化全局表征。其次,多路共识跨模态 MCCM 通过专家间动态协作与跨模态互扫,高效整合多模态的互补信息:一方面鼓励专家形成多样的特征偏好与融合策略,另一方面促使被激活专家向统一表征收敛,从而为图像融合及下游任务提供更可靠的结果。此外,本文提出一种新颖的双层自监督对比正则化损失(BSCL),在不增加模型复杂度的前提下,同时在特征层与像素层增强高频信息,并进一步提升下游视觉任务的性能。实验结果表明,该方法在红外可见光、医学、多焦点与多曝光等多类融合任务及相关下游视觉任务上均优于SOTA方案。
该论文第一作者是厦门大学人工智能研究院2022级博士生王莹莹,通讯作者是涂晓彤副教授,由丁兴号教授指导完成。
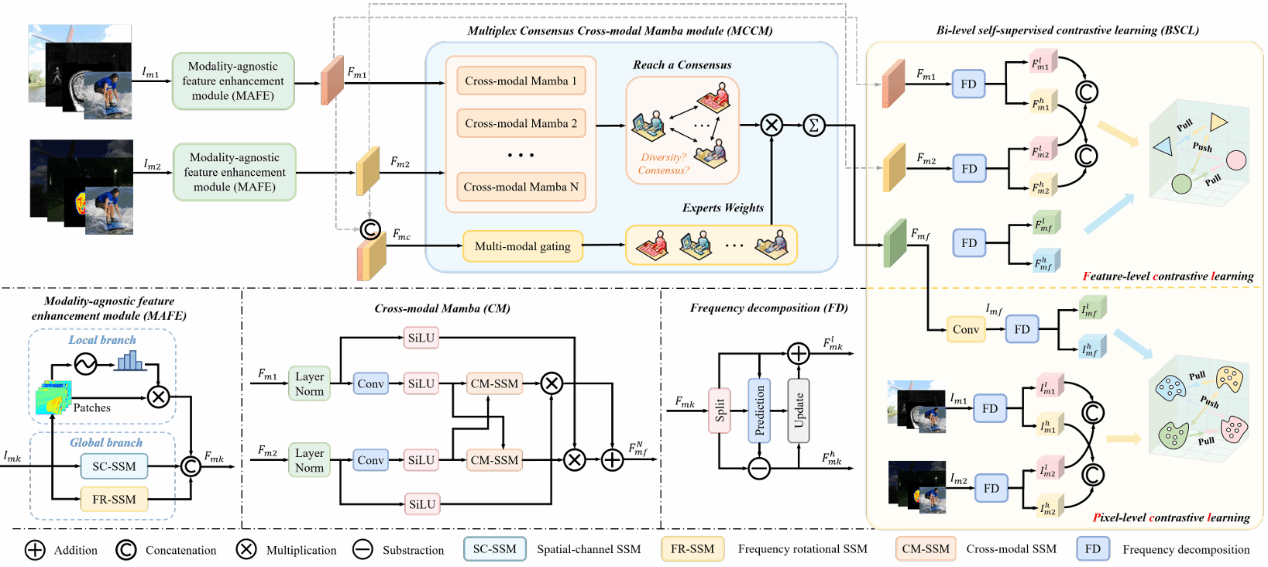
28. MMMamba: A Versatile Cross-Modal In Context Fusion Framework for Pan-Sharpening and Zero-Shot Image Enhancement(Oral)
遥感全色锐化(Pan-sharpening)旨在将高分辨率全色(PAN)与低分辨率多光谱(MS)融合,生成高分辨率多光谱图像。传统 CNN 方法多依赖通道拼接与固定卷积算子,难以适应多样的空间与光谱变化;而 Transformer 虽能实现全局交互,但计算开销大,且易弱化细粒度对应关系,难以刻画复杂语义关联。为此,本文首次将上下文条件(in-context conditioning)范式引入全色锐化,并提出跨模态上下文融合框架 MMMamba。该方法基于 Mamba 架构,在保持强跨模态交互能力的同时实现线性计算复杂度。其次,为充分释放上下文条件的潜力,本文设计了一种新颖的多模态交错(MI)扫描机制,通过在空间上将PAN和MS的相应信息单元(token)交错排列,促进了两种模态间高效、直接的双向信息交换。此外,该框架具备卓越的零样本泛化能力:仅针对全色锐化任务训练后,模型无需任何微调即可直接应用于多光谱图像的超分辨率任务。在多个基准数据集上的大量实验证明,MMMamba在全色锐化和零样本图像增强任务中均一致性地优于现有的SOTA方法。
该论文第一作者是厦门大学人工智能研究院2022级博士生王莹莹,共同一作何炫华(香港科技大学)、伍宸(中国科学技术大学),通讯作者是车昊轩(华为诺亚方舟实验室),由丁兴号教授指导完成。
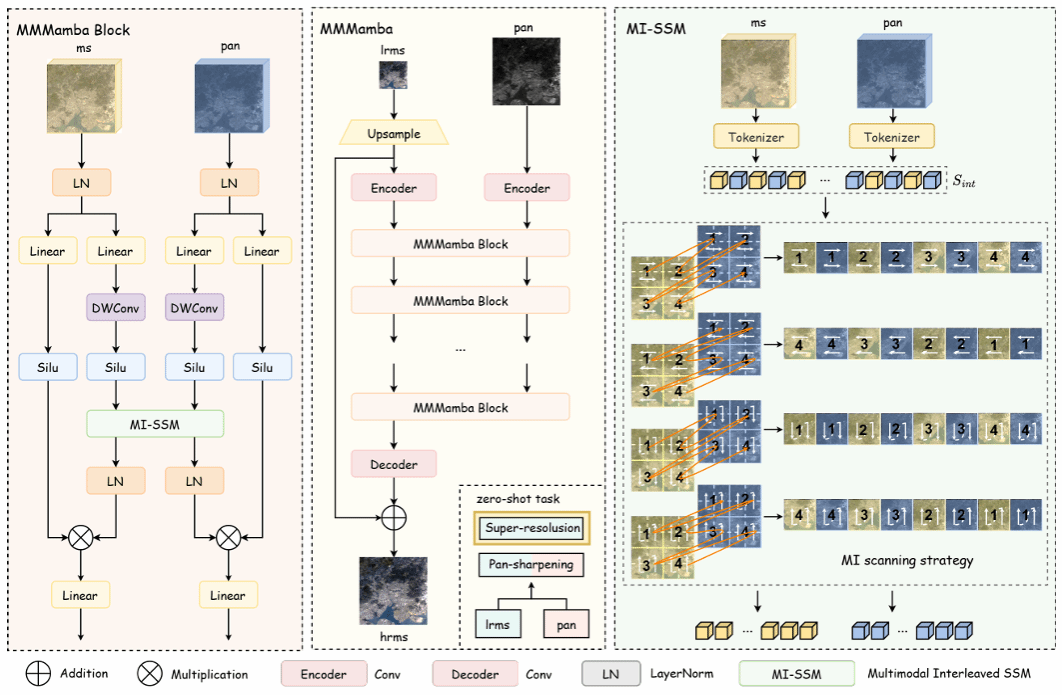
29. Cross-Field Interface-Aware Neural Operators for Multiphase Flow Simulation
多相流系统由于其复杂的动态行为、场的不连续性以及相间相互作用,对传统数值求解器提出了巨大的计算挑战。尽管神经算子为这类问题提供了高效的替代方案,但在这些系统中往往难以实现高分辨率的数值精度。这一局限主要源于多相流固有的空间非均匀性以及高质量训练数据的稀缺。在本研究中,我们提出了一种新的框架——界面信息感知神经算子(Interface Information-Aware Neural Operator,简称 IANO),该框架通过显式引入界面信息作为物理先验来提升预测精度。IANO 架构包含两个关键组件:(1)界面感知的多函数编码机制:该机制联合建模多个物理场与界面信息,从而捕捉界面处的高频物理特征。(2)几何感知的位置编码机制:该机制进一步建立界面信息、物理变量与空间位置之间的关系,使模型即便在低数据场景下也能实现逐点的超分辨率预测。实验结果表明,IANO 在多相流模拟中相较于基线模型在精度上提升了约 10%,并在数据稀缺和噪声扰动条件下保持了良好的鲁棒性。
该论文的共同第一作者是厦门大学信息学院王贞众助理教授和2025级硕士生张昕,通讯作者是江敏教授,由2022级本科生廖军共同合作完成。
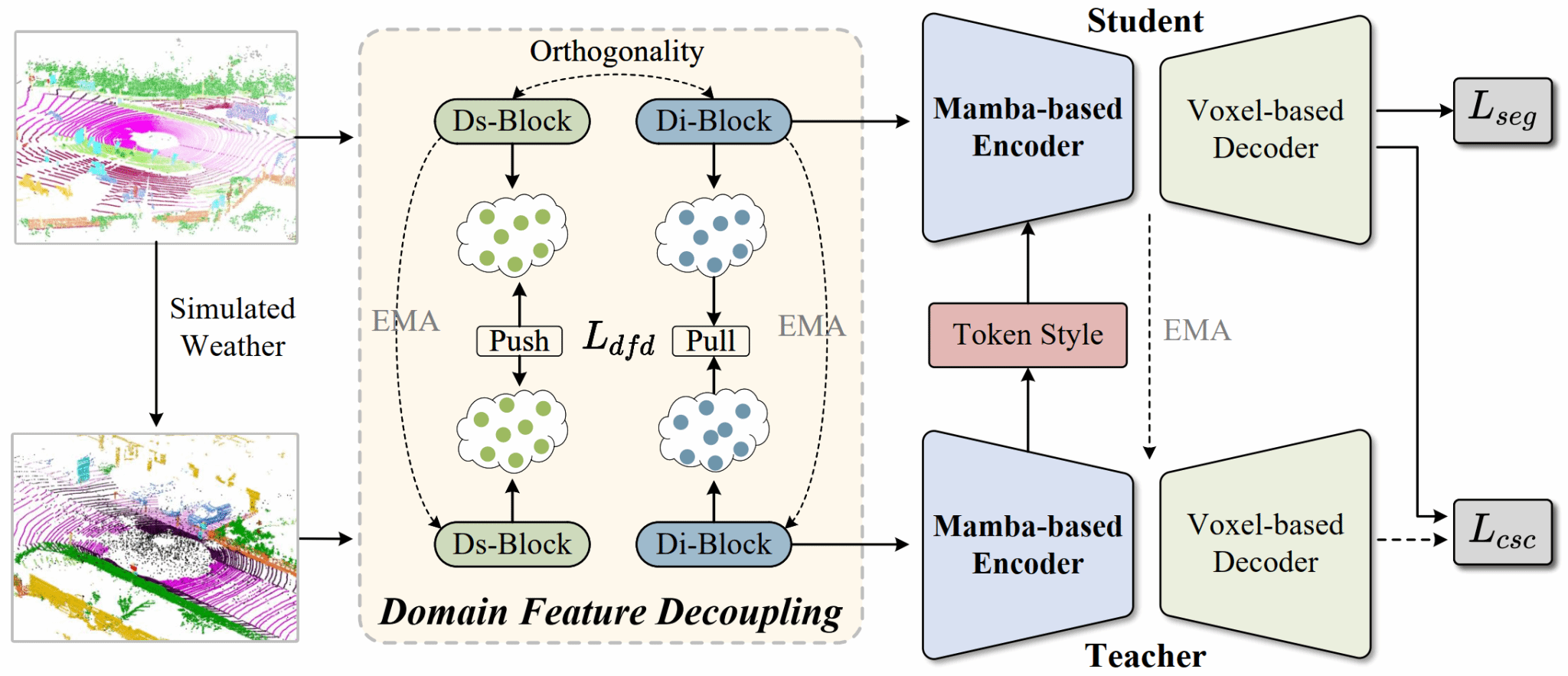
30. BeyondSparse: Facilitating Mamba to Enhance Cross-Domain 3D Semantic Segmentation in Adverse Weather
该论文探索了恶劣天气下,空间噪声的注入影响LiDAR点云的反射率,加剧域分布差异化,降低3D模型泛化性能的问题。当前方法主要依赖于3D稀疏卷积架构处理点云数据。但受限于局部感受野,难以有效捕获不同稀疏度点云的全局几何特征,导致跨域迁移能力受限。因此,本文创新性地将状态空间模型集成到3D稀疏卷积的体系结构中,序列建模所有特征以学习域不变表示。首先,设计领域特征解耦模块,在序列建模之前将特征分离为域不变特征和域特定特征,为后续跨域表征对齐奠定基础。其次,设计基于Mamba的3D编码器,将状态空间模型与3D稀疏卷积块集成,实现对体素化点云的全局序列化建模,突破局部感受野限制。最后,引入风格增强模块,捕获输入数据的内在属性,强化域不变表示的鲁棒性。该方法的提出有效缓解了恶劣天气下点云分布偏移导致的性能退化问题。实验结果证明,在场景SemanticKITTI→SemanticSTF和SynLiDAR→SemanticSTF下实现点云域泛化和域自适应的突破性进展,显著超越当前最先进的方法。
该论文的第一作者是厦门大学信息学院2025届博士毕业生吴垚,通讯作者是其导师曲延云教授和张亚超助理教授,由2025届硕士毕业生邢明炜,汉江国家实验室王方勇教授,美国加利福利亚大学张晓沛教授共同合作完成。
31. OmniEvent: Unified Event Representation Learning OmniEvent
简介:事件相机因其超高的动态范围和时间分辨率,在计算机视觉领域日益受到关注。然而,由于事件数据流的非结构化分布和时空非均匀性,现有方法主要依赖特定任务的设计,导致模型难以在不同任务间复用。为此,本文提出了首个统一的事件表示学习框架OmniEvent,旨在消除对特定任务设计的需求。OmniEvent在空间域和时间域上独立进行局部特征聚合与增强,以避免时空不均的问题。此外,采用空间填充曲线以极高的内存和计算效率实现大感受野,并最终通过注意力机制融合时空特征。在3个代表性任务和10个数据集上均取得了SOTA性能。
该论文第一作者是博士生严伟奇、硕士生林晨露,通讯作者是臧彧副教授、蔡志鹏研究员(Meta AI)。并由汪有标、林修弘、施阳阳研究员(Meta AI)、刘伟权副教授(集美大学)共同合作完成。
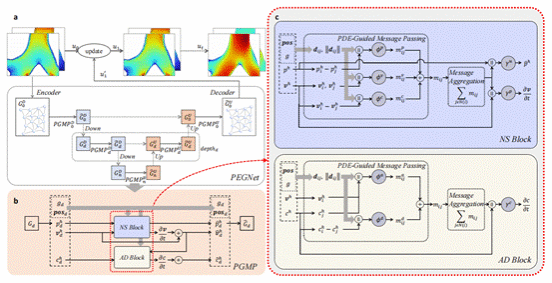
32. PEGNet: A Physics-Embedded Graph Network for Long-Term Stable Multiphysics Simulation
对受偏微分方程(PDE)支配的物理现象进行准确且高效的模拟,是科学与工程领域的重要基础性问题之一。传统的数值求解器虽然功能强大,但计算代价往往十分高昂。近年来,数据驱动方法逐渐成为替代方案,但它们常常面临误差累积与物理一致性不足的问题,尤其是在多物理场耦合与复杂几何结构场景下表现欠佳。为应对这些挑战,我们提出了 PEGNet(Physics-Embedded Graph Network),一种物理嵌入式图神经网络,通过PDE引导的消息传递机制(PDE-Guided Message Passing)重新设计了图神经网络的结构。该模型将对流、粘性、扩散等关键的PDE动力学过程分别嵌入到独立的消息函数中,使得物理约束能够自然地融入网络的前向传播,从而生成更稳定且物理一致性更强的预测结果。此外,PEGNet采用了层次化架构以捕捉多尺度特征,并在损失函数中引入了物理正则项,以进一步强化对控制方程的遵循。我们在多个基准测试上评估了PEGNet的性能,包括针对呼吸气流与药物输送的自建数据集。实验结果表明,PEGNet在长期预测精度与物理一致性方面均显著优于现有方法。
该论文第一作者是2025级硕士研究生杨灿,通讯作者是江敏教授。并由王贞众助理教授、刘俊源、龚云鹏共同完成。
33. RIS-LAD: A Benchmark and Model for Referring Image Segmentation in Low-Altitude Drone Imagery
指代图像分割(Referring Image Segmentation,RIS)是视觉-语言理解中的核心任务,旨在根据自然语言描述分割出图像中的特定目标。尽管该技术在遥感领域已取得长足进步,但低空无人机(Low-Altitude Drone,LAD)场景下的指代分割仍鲜有研究。本文提出了RIS-LAD,这是首个专为低空无人机场景打造的细粒度指代图像分割基准数据集,包含13,871组从真实无人机航拍素材中精心标注的图像-文本-掩码三元组,特别关注小目标、密集杂乱物体以及多视角情况。与此同时,本文提出了一种语义感知自适应推理网络(Semantic-Aware Adaptive Reasoning Network),不再将全部语言特征统一注入网络,而是将语义信息分解并自适应地路由至不同阶段。
该论文第一作者是厦门大学信息学院2024级博士生叶锴,通讯作者是曹刘娟教授,由戴平阳高级工程师、2023级本科生栾英石、2025级硕士生孟广樾、2023级本科生陈朱迪共同合作完成。
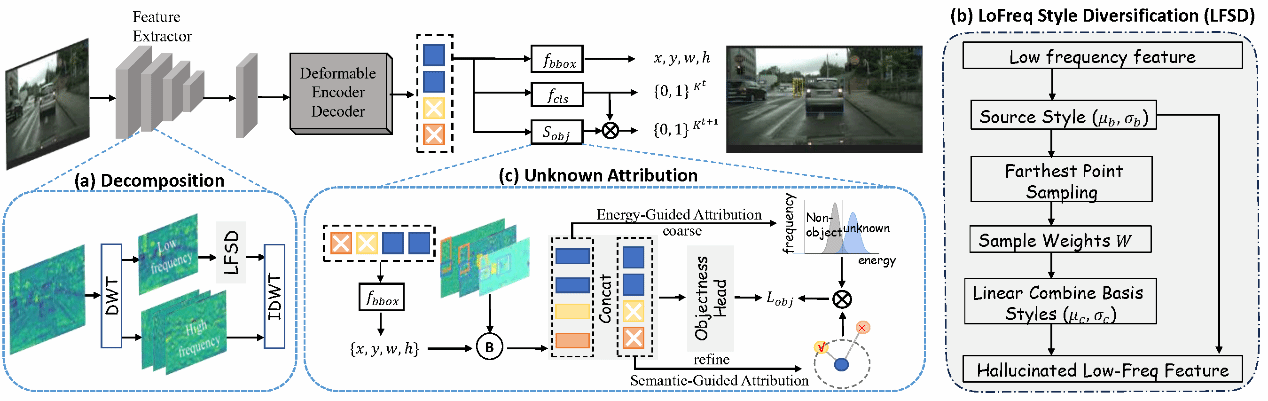
34. Decompose and Attribute: Boosting Generalizable Open-Set Object Detection via Objectness Score
开放集目标检测(Open-set Object Detection, OSOD)的目标是在识别已知类别目标的同时,定位先前未见过的实例。然而,真实场景中往往同时存在域偏移与未知类别的问题。现有的 OSOD 方法通常忽略域偏移,依赖仅在源域上训练的特征表示。这些表示往往将域特定的风格与语义内容纠缠在一起,从而削弱了模型对未知域和未知类别的泛化能力。为应对这一挑战,我们提出了一个统一框架——Decompose and Attribute (DOAT),旨在将域特定风格与语义结构解耦,从而实现更具泛化能力的目标检测。DOAT 通过基于小波的特征分解,显式地分离并建模了域偏移与类别偏移。针对域偏移,DOAT 在风格子空间内对低频分量进行扰动,以模拟多样化的域特征;针对未知类别的发现,利用高频分量,通过归因机制融合小波能量与语义距离,以估计目标性得分。
该论文的共同第一作者是厦门大学人工智能研究院2024级博士生袁与炫和2024级硕士生魏励晨,通讯作者为黄悦教授,由唐路垚(香港大学),陈超奇(深圳大学)、丁兴号教授等共同完成。
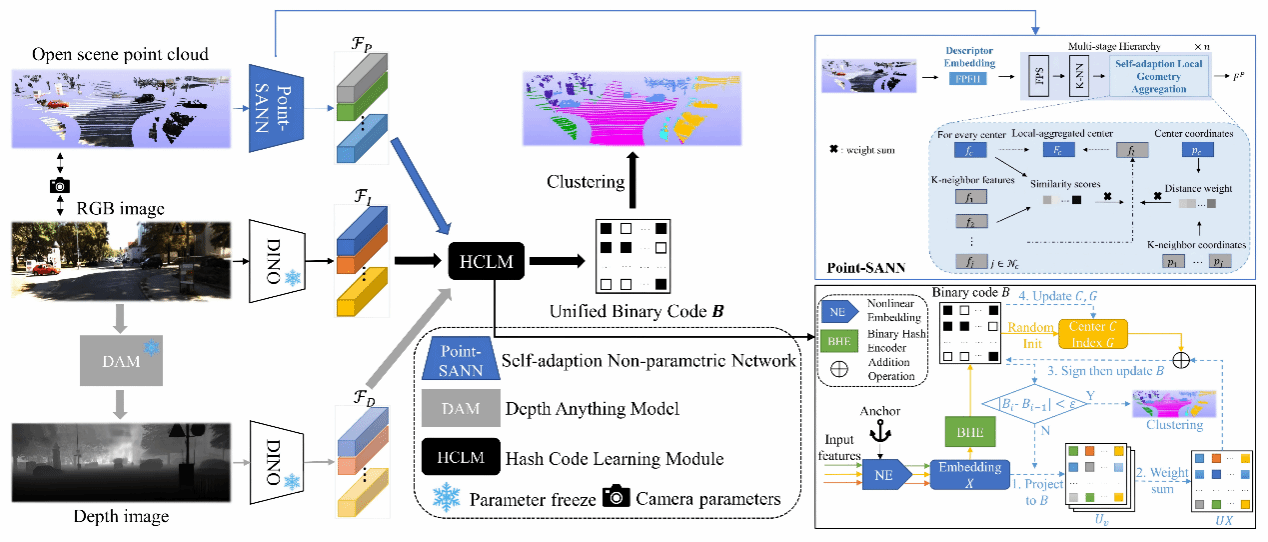
35. xMHashSeg: Cross-modal Hash Learning for Training-free Unsupervised LiDAR Semantic Segmentation(Oral)
本文针对无监督、无需训练的LiDAR点云语义分割问题,提出了一种新的跨模态哈希学习框架xMHashSeg。现有方法在面对新场景或新类别时通常需要大量重新训练,依赖标注数据或模型微调。为解决这一挑战,xMHashSeg充分利用2D图像与3D点云的互补信息,在完全不使用标签、不进行任何训练的前提下实现语义分割。本文设计了一种新型非参数网络Point-SANN,用于从原始LiDAR点云中提取对密度变化鲁棒的3D特征。为有效融合多模态特征,论文引入哈希码学习模块,将不同模态特征投影到统一的哈希空间中,通过协同离散表示学习和二值聚类结构优化,获得一致且判别性强的哈希编码用于聚类分割。在多个公开数据集上的实验验证了方法的优越性。
该论文第一作者是厦门大学人工智能研究院2024级博士生张嘉龙,通讯作者是曲延云教授与张亚超助理教授,由吴垚(福州大学)、 王方勇(汉江国家实验室)等共同合作完成。
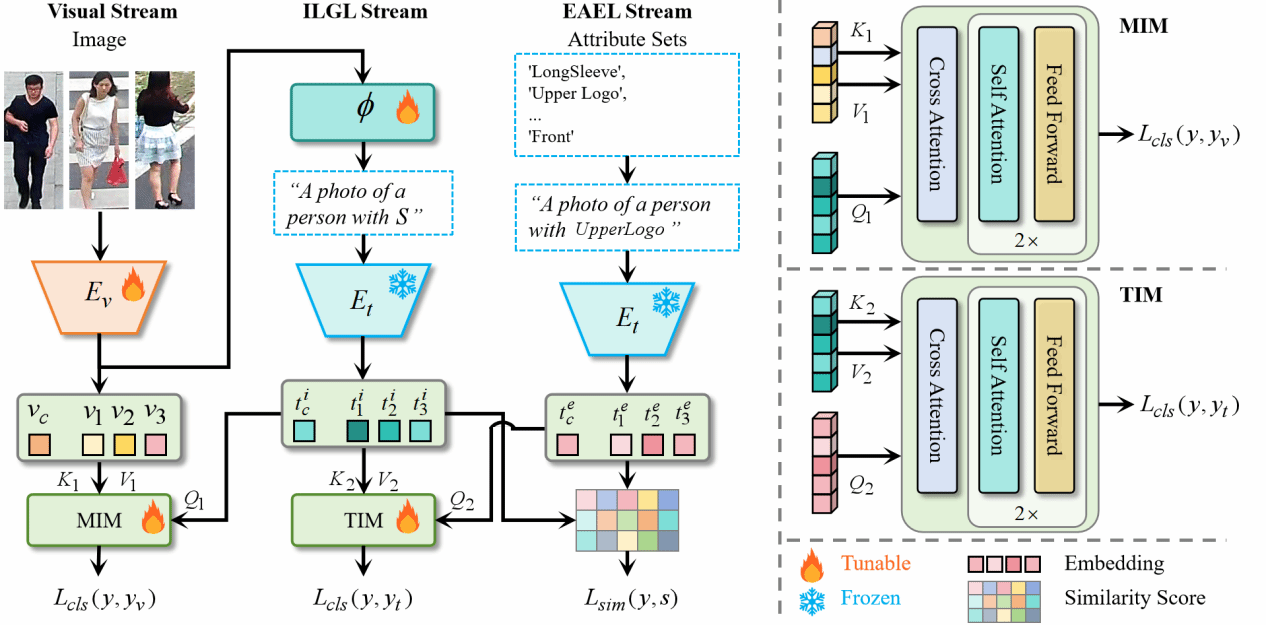
36. Joint Implicit and Explicit Language Learning for Pedestrian Attribute Recognition(Oral)
本文研究行人属性识别(PAR)任务,PAR因其在视频监控和行人分析中的广泛应用而日益受到关注。一些文本增强方法通过将属性转换为语言描述来解决这一任务,以促进属性与视觉图像之间的交互学习。然而,这些通用语言无法唯一描述不同的行人图像,缺乏个体特征。本文提出一种联合隐式与显式语言引导增强学习(JGEL)方法,通过双语言学习将每个行人图像转换为语言描述,以有效学习增强的属性信息。具体而言,我们首先提出隐式语言引导学习(ILGL)流,将视觉图像特征投影到文本嵌入空间以生成伪词标记,隐式建模图像属性并提供个性化描述。此外,我们提出显式属性增强学习(EAEL)流,显式引导ILGL生成的伪词标记与行人属性对齐,从而有效将伪词标记与文本嵌入空间中的属性概念对齐。大量实验表明,JGEL在提升PAR性能及挑战性零样本PAR任务方面具有显著优势。
该论文第一作者是厦门大学信息学院2024级博士后张玉康,通讯作者是王菡子教授,由谭磊、卢杨副教授、严严教授共同合作完成共同合作完成。
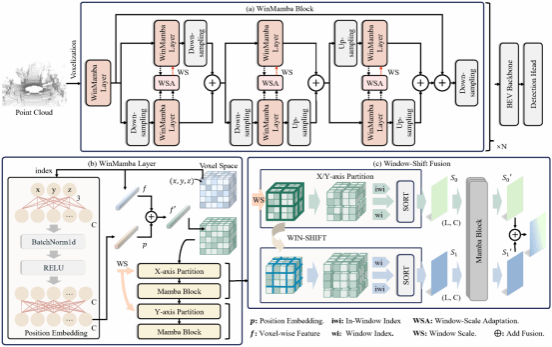
37. WinMamba: Multi-Scale Shifted Windows in State Space Model for 3D Object Detection
三维目标检测是自动驾驶感知的重要任务,但在最大化计算效率和捕捉长距离空间依赖关系方面仍存在挑战。Mamba模型凭其线性状态空间设计,能以更低的计算成本捕捉长距离依赖,从而在效率与精度间取得良好平衡。然而,现有方法依赖固定窗口内的轴对齐扫描,不可避免地丢失部分空间信息。为此,本文提出基于Mamba的三维特征编码主干网络WinMamba。首先,为增强主干网络的多尺度表征能力,引入了一个窗口尺度自适应模块,在采样过程中对不同分辨率下的体素特征进行补偿。其次,为了在线性状态空间中获取丰富的上下文线索,引入了可学习的位置编码和窗口移位策略。在KITTI和Waymo数据集上的实验表明提出的方法显著优于基线方法。
该论文第一作者是硕士生郑龙辉、博士生夏启明,通讯作者是温程璐教授。并由陈晓璐、刘昭亮、王程教授共同合作完成。
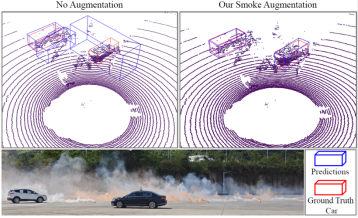
38. Physically-Based LiDAR Smoke Simulation for Robust 3D Object Detection
在烟雾等恶劣天气下,激光雷达点云往往稀疏且噪声显著,导致三维目标检测性能严重下降。为此,本文提出了一种基于物理原理的烟雾仿真框架,用于合成高保真烟雾点云并增强模型感知鲁棒性。首先,构建了基于三维流体动力学的烟雾仿真系统,模拟烟雾粒子的空间扩散与时间演化;结合物理精确的激光雷达感知模块,捕捉光束衰减、散射与多路径效应等复杂光学交互,生成高保真、物理一致的烟雾点云。其次,使用基于距离图像的数据融合策略将仿真烟雾点云集成至真实LiDAR数据集,准确模拟LiDAR扫描特性并自然引入遮挡效应。此外,构建了真实场景LiDAR烟雾数据集LiSmoke用于方法性能验证。结果表明,使用本方法合成数据训练的模型在烟雾场景中检测性能显著提升。
该论文第一作者是博士生郑世均,通讯作者是王程教授、刘伟权副教授(集美大学)。并由郭宇、臧彧副教授、沈思淇长聘副教授、程明教授共同合作完成。